Autonomous Discovery from Data
Learning Sequential Decision Making Algorithms from Data
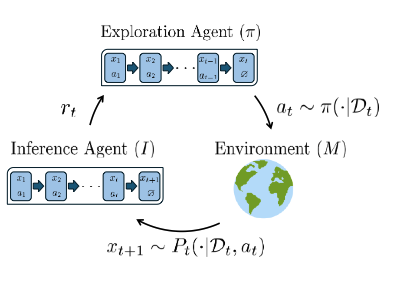
Overview
Sequential decision-making algorithms are used to interact with environments where the objective is to learn a policy that improves with data. Among others these are scenarios such as bandit problems, where one wants to compete against the best arm in hindsight, reinforcement learning domains, where finding an optimal policy is paramount, or active learning settings where the goal is to produce an accurate model of the world in as few online interactions as possible. Applications where these models are used include scenarios such as robotics and experiment design in scientific domains. Designing sequential-decision making algorithms typically involves a careful and painstaking modeling process that requires deep domain knowledge as well as mathematical proficiency in the techniques of sequential decision-making. In these works we explore an alternative way of producing algorithms for sequential decision-making domains. Instead, we will use the in-context learning abilities of transformer models to encode history dependent policies (i.e. algorithms) that will be learned from data by minimizing an appropriate loss. In our work Supervised Pretraining Can Learn In-Context Reinforcement Learning we design the Decision Pretrained Transformer (DPT) a supervised learning strategy over offline data that can be used to recover the Thompson Sampling algorithm. We expand on this line of work in our paper Learning to Explore: An In-Context Learning Approach for Pure Exploration where we introduce the In Context Pure Exploration (ICPE) algorithm. In this work learning is done via an online reinforcement learning approach. ICPE is able to recover a bayes optimal discovery strategy for sequential hypothesis testing adapted to specific problem families. Learning how to autonomously discover is an exciting area of research that our research group is really proud to be pioneering.
Papers:
Aldo Pacchiano
Assistant Professor / Visiting Scientist
My research interests include online learning, Reinforcement Learning, Deep RL and Fairness.